Serverless Geospatial
9 Minute ReadAddresscloud provides address matching, geocoding, and location intelligence in real-time - a service which has to be both accurate and fast. In this post I explore the serverless model within a Geographical Information Systems (GIS) context and explain why we chose this approach to deliver Addresscloud's geospatial applications.

Why Serverless for Geo?
This post follows my recent talk at FOSS4G UK "Geography as a Service? Serverless Architectures for Geospatial Applications", and collates a number of working notes and conversations with Mark on serverless-geo.
Whilst I subscribe to the "spatial isn't special" school of thought, it is clear that two developments are prompting developers to think beyond traditional architectures for geospatial applications:
- data volumes: hyper-connected terrestrial and aerial sensors are generating large volumes of geographic data at increasing frequencies.
- data ubiquity: customers are now normalised to interacting with geospatial data and services, and increasingly expect geography to be part of their business solution.
Serverless architectures provide an instantly scaleable application environment so that IT infrastructure may dynamically scale up and down to meet the demand of both machine and human users. To achieve real-time scaleability, serverless models abstract data storage, data retrieval and software execution away from the computer operating environment and underlying infrastructure. Higher-order serverless services have the greatest abstraction from their server environment and typically offer a higher level of scaleability.

Serverless represents a step-change in computer software architecture and provides a pathway for GIS to manage large data volumes and user demands. Serverless as an architecture is particularly relevant for three types of geospatial application:
- Systems receiving, collating, and storing data from large sensor-arrays.
- Delivery of geospatial information to a large number of users in real-time.
- Running computationally-intensive tasks that are highly-paralellizable.
The challenge behind all three use-cases is scale. Operating a serverless architecture for each of these applications mean that resources can be dynamically scaled in response to real-time demand placed upon the system. Such elasticity traditionally could not be provisioned via physical infrastructure without significant costs, hardware resources, and energy consumption.
Secret Sauce
Amazon CTO Werner Vogels recently wrote about the two components that make up modern web applications - the "secret sauce" and the "undifferentiated heavy lifting". Werner's take on serverless is that it allows companies to focus on their secret sauce - the thing that gives the application its market fit - and enables businesses to reduce labour spent on infrastructure management (the heavy lifting). The reasoning is that servers and data-stores are necessary infrastructure, but no matter how innovative or efficiently administered they are these processes will not differentiate the application from its competitors.
For geospatial applications, geography is often the "secret sauce". As geographers and developers we need, and should, focus our energy on making our data, algorithms and maps provide the best possible solution for our users. In this regard, the major advantage of serverless is that it frees developers from low-level resource administration, enabling them to focus on delivering better applications.
Scale to Zero
“My definition of Serverless also is an economic one: A serverless application is one that costs you nothing to run when nobody is using it, excluding data storage costs”. Paul Johnston, 2019
The ability to "pay as you go" using a serverless architecture versus the overheads of running physical or virtual servers at scale to meet demand is ideal for geospatial applications. Serving large, spatially contiguous data-sets, and performing intensive geographical computations are key to Addresscloud services. In addition to the time savings for infrastructure management described above, at Addresscloud we have found that it is possible to significantly reduce our compute costs by using an event-driven architecture so that we're only paying for "server" time when its needed - our applications run when they are triggered by incoming requests from our users or our internal services.
As referenced in Paul's quote, data storage costs are often considered a fixed cost, particularly when using managed disk in the cloud. However, serverless object stores, which decouple the storage medium from the data retrieval mechanism, can be used to great effect with geographic data. For instance Addresscloud hosts the OS Open Zoomstack product comprising of 2,795,138 vector tiles at no cost. See Mark's talk at FOSS4G UK "Serverless Zoomstack on AWS" for details.

Design Patterns
The elasticity of serverless resources and in particular serverless computing resource is achieved by providing an application environment that is stateless. Compute resources provided using the "functions as a service" (FAAS) model enable process execution that has no memory of preceding or future innovations of itself, nor any other information about the system except that which is loaded at runtime. Likewise, serverless data stores abstract the mechanism of object storage from information query and retrieval, and can either extend or replace traditional relational and non-relational databases.
The FAAS model of software execution provides the developer with a runtime environment without any configuration of the physical or virtual servers that run their software. The function is executed in response to either an incoming request or a scheduled task and the program ceases to run once its operation is complete and any data within the program not explicitly stored with an external service is lost. The significant advantage of this approach is that many invocations of the same program can run simultaneously in parallel (e.g. in response to requests from different users). Thus, the FAAS model is ideally suited to geospatial applications which see significant variability in scale and workload, and are highly parallelizable. Although, it should be noted that not all FAAS design patterns are necessarily serverless.
Harnessing a serverless model as an alternative to a monolithic application /database requires a re-architecting of software, and re-orienting the developers' mental model of process execution and data flow. The microservices design pattern is frequently used in serverless environments because it is complimentary to FAAS processes, however, this post from Jeremy Daly demonstrates the wide variety of architectures that can be created within serverless services.
Geographic Lookups
To create complete systems using FAAS architectures multiple individual functions can be grouped together enabling operations to be chained for data processing. One of the best examples of this we've developed and which I have talked and written about previously is our internal raster service. Using the Cloud Optimized Geotiff (COG) format we are able to store a large complex raster file in an object store, and query small subsets of this data in real-time using rasterio.
The best thing about the raster service architecture is that it is scale-free. The service can respond to ever-increasing numbers of lookup requests without additional overhead and only marginal increase in cloud costs. It should also be noted that we're able to build such a service because free and open geospatial standards are cutting edge technology (and something we plan to continue to support in the future).
The Elephant in the Room
Postgres with PostGIS is now the de-facto data storage and data processing medium for vector data in geospatial applications. As described in my talk we use PostGIS for our data pre-processing and in production for geospatial queries. Recently, Amazon Web Services has announced the general availability of its Postgres Aurora Serverless solution. Aurora is a serverless solution where a Postgres-compatible engine is scaled up and down in response to query demand, and in the case of no activity it is possible to scale to zero instances. When the service is in this "cold" state customers are only billed for data storage. Postgres instances are then created on-demand in response to SQL connection requests. This means that the potential efficiencies gained from using Aurora, particularly under variable work-loads are significant. Paul Ramsey (a core PostGIS maintainer) has written a couple of articles about the efficiencies and also potential technical adoption risk of Postgres Aurora.
Whilst the service is still only available for Postgres 9.6 I've started testing Aurora to assess its viability to run both our internal and customer-facing workloads. Testing is in early stages but the example below shows the response times for a simple point in polygon query against the Addresscloud crime model.
SELECT
sector,
burg_class,
geom
FROM
crime as d
WHERE
ST_Contains(d.geom, ST_GeomFromText("POINT(-1.08078 53.96216)",4326)
I executed the query against an Aurora instance in both warm and cold states, and performed the same query against our existing database as a control which runs using the AWS Relational Database Service (RDS). When the service is warm (two-units of computing capacity available) Aurora processed the query at the same speed as the RDS. However, when it was in a cold state it was able to initialize computing resource and respond to the query in less than 20 seconds.
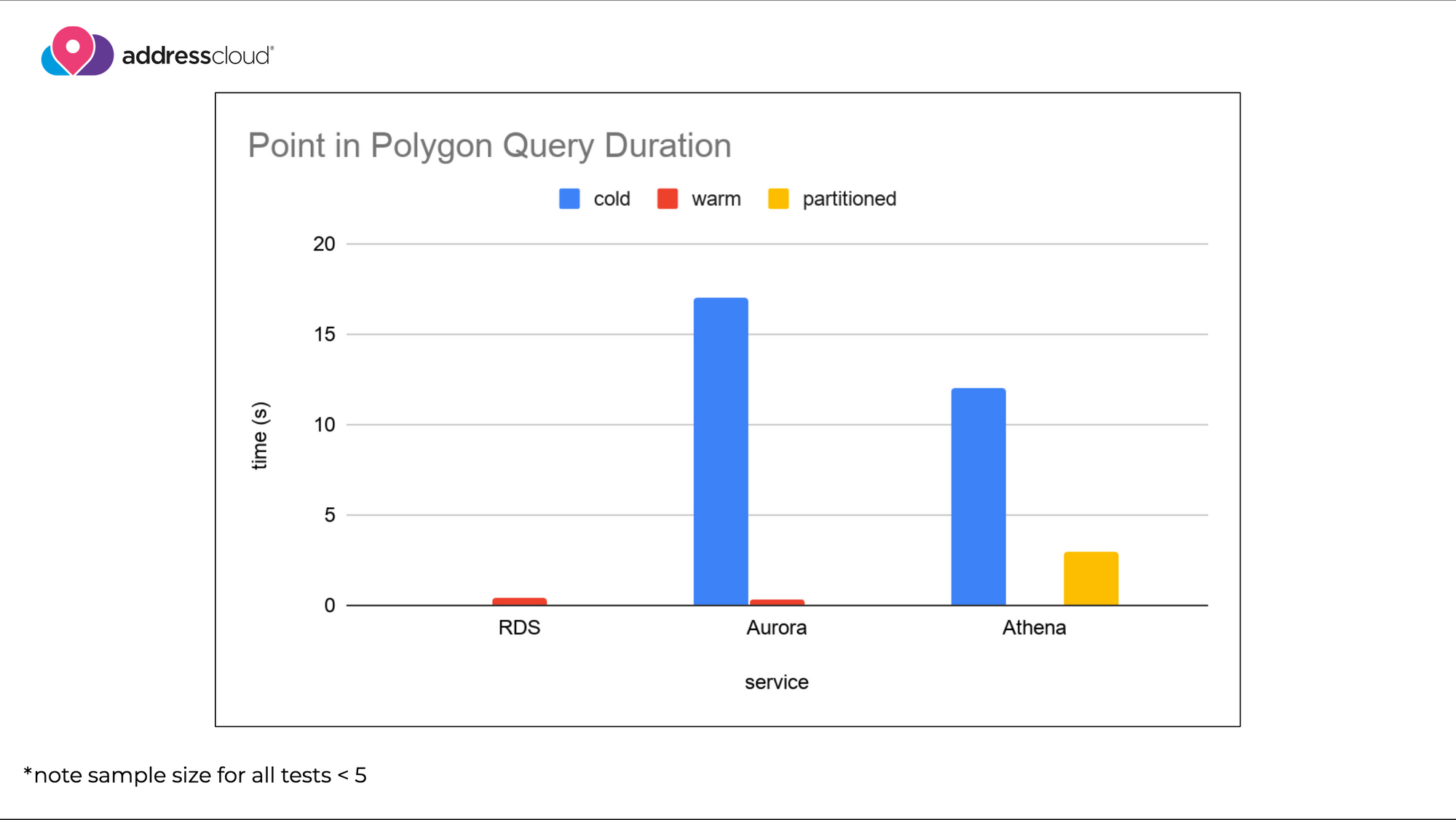
At the same time as running queries against Aurora, I wanted to push the serverless data boundaries a further and see what was possible at the far-end of the abstract serverless spectrum. AWS offers a service called Athena which can be used to process SQL queries against text-files stored in an object store. Athena has support for geospatial queries meaning that I was able to upload our crime data and perform the same point in polygon query without a database. The query was understandably slower (~12 seconds), however improved when I introduced a partitioned index using the polygon ID (~4 seconds). Obviously Athena isn't suitable for customer-facing queries in our use-case, but goes to demonstrate the potential to build time-insensitive applications without a database.
Latency, Edge, and the Future
It's an exciting time to be building geospatial tech. The volume and quality of geographic data that are now available are unprecedented. Serverless affords the opportunity to create applications without the overheads of server and database management. However, challenges still remain - the learning curve for cloud services is steep, and the time waiting for services to initialise needs to be managed to avoid increasing the appearance of application latency.
I'll post updates as we continue to test the Aurora service. We're looking forward to researching the potential of newer serverless offerings at the "edge", which combined with new coordinate reference systems that can index data client-side, might completely change the way we think about geographic data in our apps.
Addresscloud in Action
See how Addresscloud services are helping our customers solve real-world challenges.