Serverless PostGIS
5 Minute ReadThis post follows my recent presentation at the FOSS4G UK Online 2020 conference. I previously spoke about serverless data-stores for geospatial at FOSS4G UK 2019. Since then we've adopted Aurora Serverless in our production stack, using PostGIS to perform spatial queries for customer requests. In the talk I wanted to demonstrate how easy it is to setup Serverless PostGIS, and highlight some of the advantages and caveats of working with AWS Aurora Serverless. As a proof-of-concept I demonstrated serving vector tiles for buildings in London straight from Postgres - without a server! You can watch the talk below and read on for my summary and the slides.
Why A Serverless Spatial Database?
I've previously spoken on the MapScaping podcast about using serverless to build scaleable geospatial applications. Like many organisations our usage is variable and we need to be able to respond to sharp spikes in demand without impacting customer performance.
Postgres is a popular datastore for spatial data with the PostGIS extension providing a powerful set of functions for spatially querying data. Prior to AWS Aurora Serverless Postgres instances running on fleets of virtual servers had to be manually scaled up and down in response to anticipated demand. In response, we architected our stack to push as many queries as possible to other serverless data-stores and only sent the most complex spatial queries to PostGIS. However, this created something of a catch-22 situation—because our PostGIS queries are complex and long running (large, irregular polygons, intersected with ~20 other layers) a spike in customers submitting these kinds of requests would start to tax our database servers, causing a slow-down in performance.

The Road to Production
For the first time, AWS Aurora Serverless offers a way to run PostGIS in a scaleable environment. Aurora achieves this by decoupling the data-storage from the compute layer (used to perform queries) meaning that the compute layer is free to scale horizontally in response to the number of connections and load on the database. For stacks with a stateless application layer, such as Lambda functions, Aurora complements this scaleability through a Data API. This HTTP interface allows queries to be submitted without the need for manual database connection pool management, which is tricky to achieve consistently outside a traditional server environment.
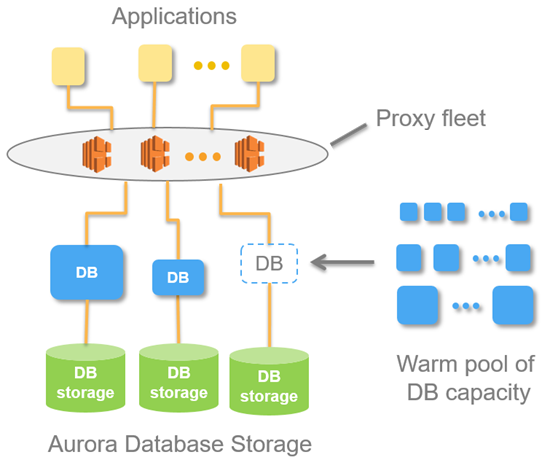
To use Aurora Serverless in production we updated our application layer queries to use the Data API and moved the relevant datasets across to a new database instance. One of the caveats that I highlight in the talk is that there's currently no way to create an Aurora Serverless instance from an RDS snapshot, meaning that tables must be moved over manually using pg_restore, or ogr2ogr etc.
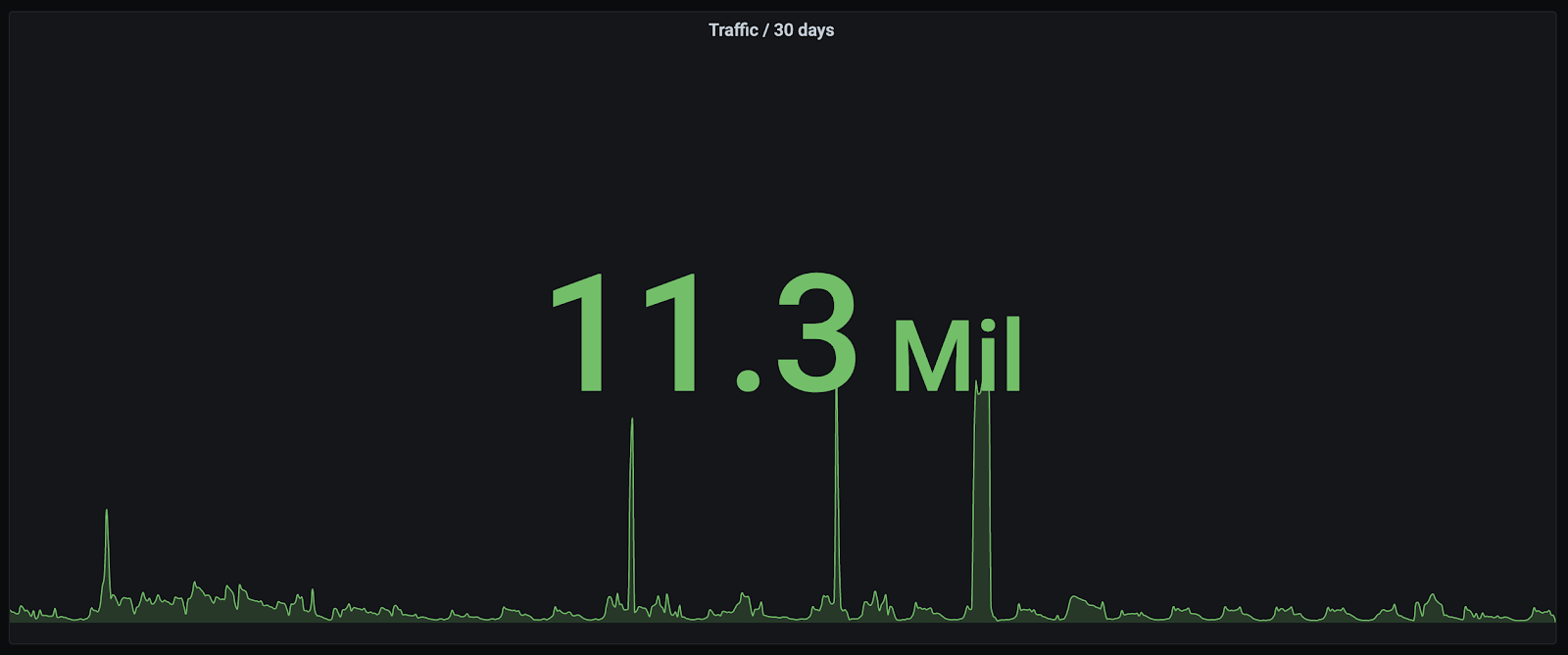
We've been running our serverless PostGIS instance for six months and its been a great success. We've serviced ~800k queries against the database and only seen five scaling events in response to high-load. In each instance, as customer request latency increased, the database scaled automatically and latency reduced to the operating norm.
Lessons Learned
A question was asked in the session about the 1 MB limit on the Aurora Data API - which was a good prompt for me to clarify our architecture. In this application we're not returning geometry data so the response payloads are small. In-house we're building on other Aurora Serverless instances for development (taking advantage of the cost-savings at evenings and weekends when the database is scaled-down) and traditional RDS instances with standard PG connections for data-intensive tasks.
During our use in production we've seen one outage of our database where the compute instances in the region went offline (due to hardware failure). Currently, Aurora Serverless replicates the data-layer across multiple availaility zones, but only offers compute instances in one zone at a time. In case of failure Aurora "self-heals" by moving the compute layer to another zone. This is exactly what happened in our case, and the database was available again four minutes after the first connection drop. Its worth noting that Aurora Serverless isn't currently backed by an AWS Service Level Agreement most likely due to the compute layer only operating in one zone at a time.
This is a trade-off worth making for the functionality provided by PostGIS in our application. The service is designed to deal with such outages gracefully and with minimal impact to customers. In the past, for more mission-critical systems, I've used RDS instances with multi-availability zones and even multi-region deployments, although I've still had to deal with hardware-level outages even in those configurations. It would be good to see an SLA from AWS for Aurora Serverless in the future; for now we're definitely adopting serverless PostGIS wherever possible as it's a great addition to the geospatial application stack.
Addresscloud in Action
See how Addresscloud services are helping our customers solve real-world challenges.